TCP/UDP & 可靠的传输
前言
春招的面试被问到过UDP怎么实现可靠的传输,当时都是仅仅凭着自己对TCP三次握手四次挥手的理解自己瞎说,面试官的反馈肯定都是不满意,说起来自己其实对TCP的理解也不深入,它是如何保证可靠传输的几个机制都都只知道这几个模糊的概念,花点时间好好看看,写下这篇文章让自己加深印象
TCP实现可靠传输的几个机制
确认机制
序号——序号的增加是和传输的字节相关的。TCP在传输数据时的序列号(Sequence Number)不是以报文段来进行编号的,而是将该连接生存周期内的所有数据当做一个字节流,按照字节流中的每个字节进行编号。每个TCP数据包中的数据大小不一定相同。在三次握手的连接建立之初,双方都会规定好初始的序号x和y,TCP每次传送的序号字段值表示所要传送的本报文中的第一个字节的序号。
确认——TCP的数据确认送达(ACK),是对接收到的数据的最高序列号的确认,并向发送方返回下一次期望的TCP数据包的序列号。如A->B,A当前序号是100,数据长度是50,B返回的确认号就是151给A。
效率提高——提高网络利用率和传输效率,例如TCP可以一次确认多个数据报,如果接收方接收到了151,201,301,那么只需要对301数据报确认即可,收到301意味着前面的都已经确认过。
不能跳着确认——接收端在确认时,只能确认最大的连续收到的包,例如发送端发了1,2,3,4,接收端收到了1,2,4,只能回3,回复连续收到的最大包+1的序号。
如果发送方在规定的时间内没有收到返回,超过规定时间后就将未被确认的数据重新发送,接收方如果收到的数据存在差错,也会直接丢弃此报文,不返回确认信息。更多详细的重传机制后面细讲。
重传机制
有了前面的确认机制,在数据报传送发生错误时,需要重传机制来保证传输完整。
超时重传
如果是阻塞式传输的话,意味着没有收到确认就一直四等,造成巨大的资源浪费,所以设定一个时间timeout,分为两种,一种是只重传超过timeout的包,另一种是重传timeout之后的所有包。
快速重传
相对于超时重传,这种机制不以时间驱动而以数据驱动,前一种方法是超过一定时间未收到就重传,快速重传是连续收到几次相同的ACK就重传,例如A->B,连续发1、2、3、4、5,假设期间2数据报因为某些原因没有到达,则B在收到3、4、5的时候继续返回序号为2的ACK,A在连续收到3次序号为2的ACK后,得知序号为2的包没有到达,马上重传2。
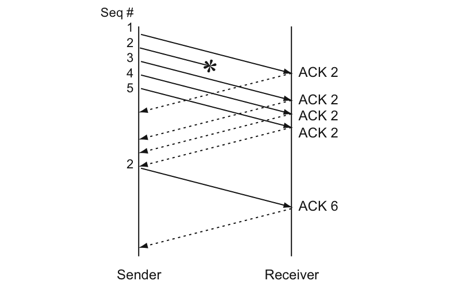
但也存在问题,A并不知道2之后的是不是被对方收到了其他的数据,不知道三次返回的序号2是谁传回来的。
Selective Acknowledgment(SACK)
这种方式基于快速重传的方法,只是在TCP头里加一个叫SACK的东西,接收方在接收缓冲区中记录好我当前缺少的部分,返回时向发送方汇报缺失内容。
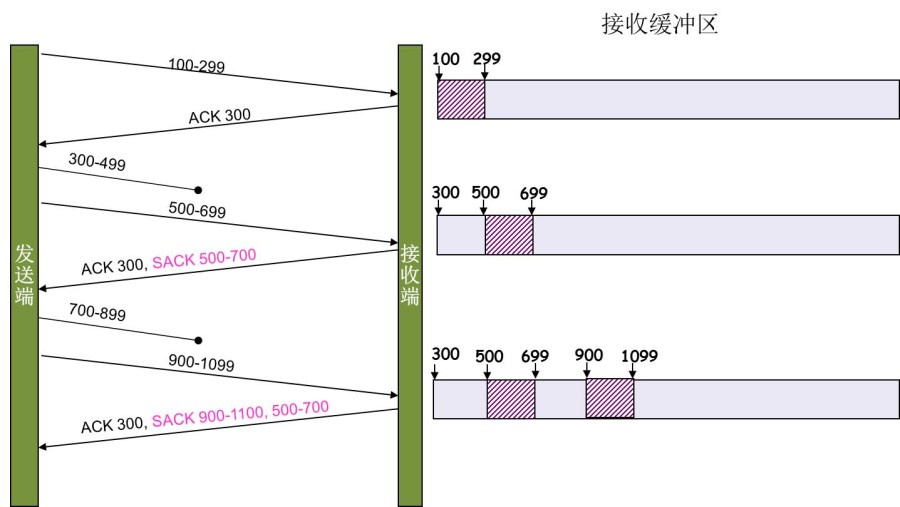
这种优化的快速重传需要两方协议都支持才行。
滑动窗口
TCP主要解决的是可靠的传输和包乱序的问题,滑动窗口是TCP引入的一种网络控流技术,TCP必须要知道网络传输中实际的数据处理带宽或者说是数据处理速度,这样才不会引起网络拥塞导致丢包。
AdvertisedWindow
Sliding Window是一个被设计来做网络流控的技术,TCP头里有一个字段叫Advertised-Window,这个字段是接收端返回给发送端告诉发送端自己还有多少的缓冲区可以接收数据,下次发送端发送数据就会按照这个接收端的处理能力来发送数据。要理解滑动窗口先看一下TCP缓冲区:
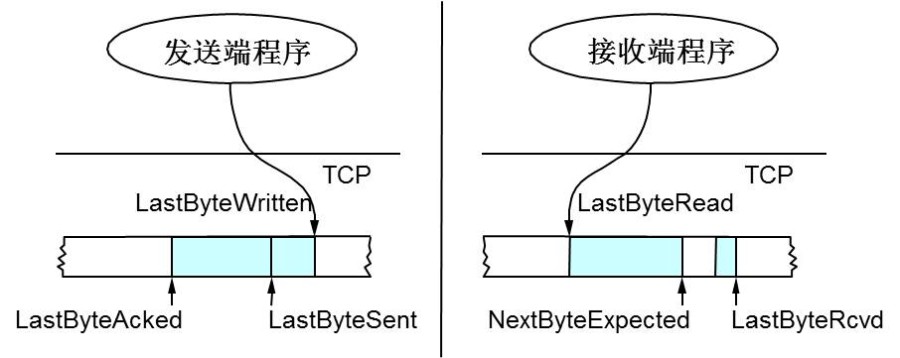
接收端里的LastByteRead表示上层应用正在读的地方,NextByteExpected表示收到的连续包的最后一个位置,LastByteRcved表示收到的包最后的一个位置,连续包和最后位置的包之间是有间隙的,表示中间还是有数据没有到达
发送端中LastByteRead表示被接收端Ack过的位置,LastByteSent表示发送出去了,但是还没收到成功确认的Ack,LastByteWritten表示上层应用正在写的地方。
因此,前面说到过的AdvertisedWindows的计算方式为:
AdvertiedWindow = MaxRcvBuffer - LastByteRcvd - 1
这个窗口就是用来控制发送数据大小的,确保接收方可以处理
Sliding Window
下面是发送方的滑动窗口的示意图:
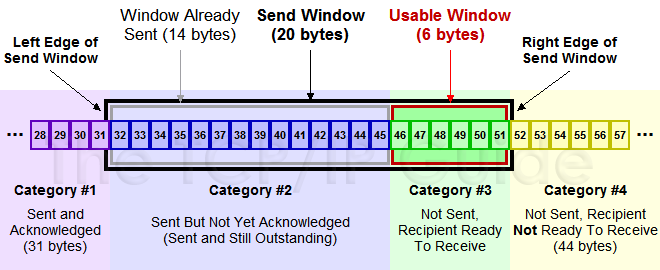
黑框部分也就是滑动窗口
- Category#1代表的是已经收到Ack确认的数据
- Category#2代表已经发送但是还未收到Ack的数据
- Category#3代表按照接收方缓冲区大小计划发出的数据
- Category#4代表窗口以外的数据,接收方空间不足以现在发送
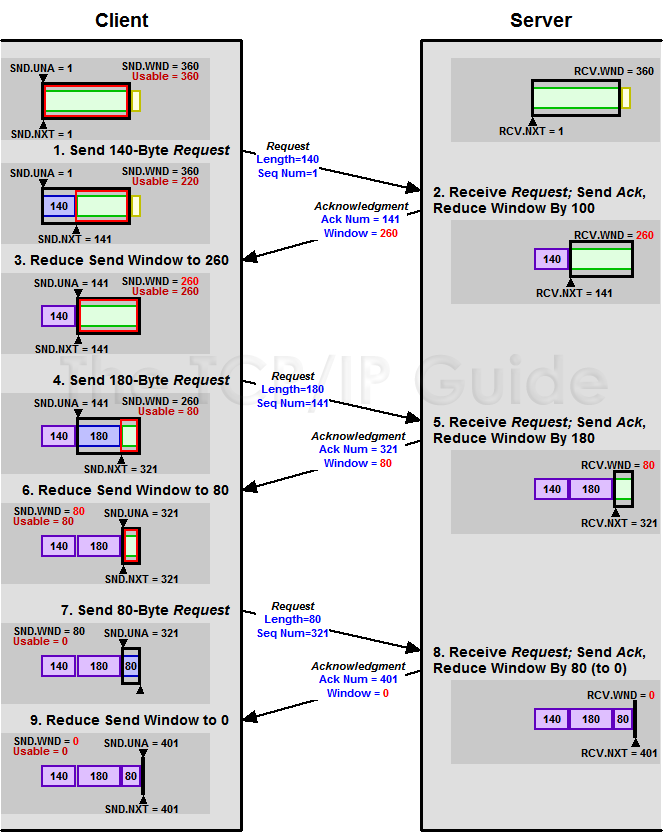
下面是一个接收端使用滑动窗口控制发送端的过程,结合上述描述和AdvertiedWindow配合理解:
Zero Window
在上图中,可以看到接收端数据处理很缓慢,返回的Window大小越来越小,最后一次返回的Window = 0,这种情况下,发送端知道接收端缓冲区已经没有地方了就不会再发送数据了,这就有个问题,发送端不发数据了接收方也没法通知发送方Window Size可用了。
为了解决这个问题,TCP使用了Zero Window Probe技术,在Window = 0之后,发送方会发ZWP包给接收方,让接收方来Ack他现在的Window大小,不同的实现情况下会设置不同的次数和不同的时间。
PS:*该技术可能会被DDoS攻击,攻击者在TCP连接建立完成后向发送方不断的发送带有Window = 0的Ack,发送方就停止发送并且发送ZWP包,服务器资源就被渐渐耗尽*
Silly Window Syndrome
像上面的那种情况,如果接收方太忙,不能及时取走Receive Window里的数据,会导致最后只有几个字节的Window来传输数据,而一次传输只传这么少量的数据很不划算,如果数据包用不满整个带宽的话会浪费大量的资源。
这个问题的解决思路从接收端和发送端两边都有解决思路,接收端设置一个阈值,小于该阈值的情况下都是Ack(0)把Window关了,等到处理后大小够大了以后再重设Window;发送端主要思路是做延时处理,设置阈值,或者是收到Ack才发数据,其他时间段都是做数据积累
拥塞算法
TCP利用滑动窗口做到了流控还是不够,还需要知道整个网络上的事。例如如果网络延时增加,导致大量丢包,没有拥塞处理的情况下,TCP只会重传数据,这样只会导致网络的负担更加重,甚至拖垮一个网络。因此TCP必须知道整个网络的情况,而且主体的设计思想为:TCP不是一个自私的协议,当拥塞发生时,做出自我牺牲,让出资源出来,不抢占少占有。
拥塞算法主要是四个部分:
- 慢启动
- 拥塞避免
- 拥塞发生时快速重传
- 快速恢复
慢启动
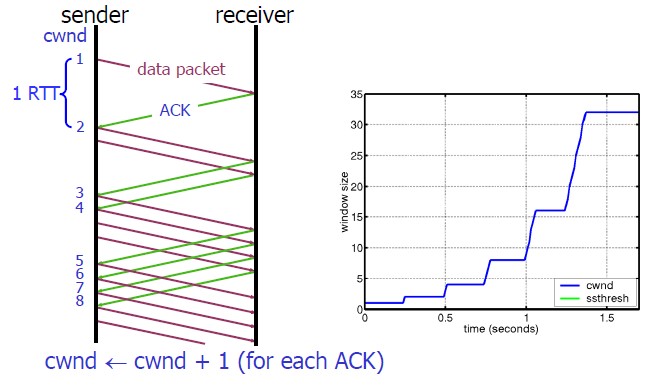
慢启动的过程很好理解,就是在加入连接的过程中,一点点提速。如下图所示,连接建立好以后,cwnd慢慢增加,每当收到一个Ack,cwnd线性上升,每隔一个RTT,cwnd指数上升。上升也不是无止境的,有一个slow start threshold,当cwnd > ssthresh时进入“拥塞避免算法”。
拥塞避免
慢启动在双重递增的情况下可以达到无限增长,因此设置了一个ssthresh,cwnd到达ssthresh后,每当收到一个Ack:cwnd增加一个自己的倒数,每过一个RTT:cwnd自增1。
拥塞时状态
当发生丢包时,有两种解决思路:
第一种是降低sshthresh的值(sshthresh = cwnd / 2),重置cwnd为1,重新开始慢启动的过程;
第二点是快速重传的方法,cwnd保留一半(cwnd = cwnd / 2),sshthresh = cwnd,进入快速恢复方法。
快速恢复
快速重传和快速恢复一般一起使用,前面说过快速重传有3次Duplicated Acks。
当发送方连续收到三个重复确认时,就把慢开始门限减半(cwnd = cwnd / 2),这是为了预防网络发生拥塞。注意,接下来不执行慢开始算法。
由于发送方现在认为网络很可能没有发生特别严重的阻塞(如果发生了严重阻塞的话,就不会一连有好几个报文段到达接收方,就不会导致接收方连续发送重复确认),因此与慢开始不同之处是现在不执行慢开始算法(即拥塞窗口的值不设为1个MSSS),而是把拥塞窗口的值设为慢开始门限减半后的值,而后开始执行拥塞避免算法,线性地增大拥塞窗口。
UDP实现可靠传输的思路
UDP不属于连接型协议,且资源消耗小,处理速度快,通常音频、视频传输时用的比较多,因为即使偶尔丢失一两个数据包,也不会对结果产生太大影响。
UDP要实现可靠传输,在传输层已经无法保证可靠传输了,只能依靠应用层来实现,实现的要点主要是确认机制、重传机制、窗口确认等。目前已经有的开源项目基于UDP实现了可靠的数据传输:RUDP、RTP、UDT。
开源协议
RUDP:提供拥塞控制的改进、重发机制及淡化服务器算法等机制,允许TCP方式下的流控行为。
RTP:该协议被用来解决音频和视频传输的功能,解决了TCP在这些应用上“慢”启动带来的问题,传输模型可以单点和多点传输。RTP协议在应用层工作,利用多路复用和校验,消除丢包带来的影响。RTP提供的服务包括有效的负载识别、序列编号、时间戳和投递监听。
UDT:主要目的是支持高速广域网上的海量数据传输,引入了拥塞控制和数据可靠性控制机制,面向连接的双向应用协议,发送方依据流量控制和速率控制来发送应用数据,接收者接受数据包和控制包,根据接收到的包发送控制包。
主要思路
主要解决两个问题:丢包和包的顺序的问题
解决思路:
- 给每个包编号,按照包的顺序接收并存储
- 增加确认机制
- 重传机制
- 窗口流量控制机制
-> ①UDP数据包+序列号 ②UDP数据包+时间戳 ③应答确认
TCP已经足够复杂了,用UDP来实现TCP其实是个很没意义的事情,如果不考虑完整实现TCP的功能,从这个角度来想,依据特定的需求来看,如果希望在某些情况下UDP优于TCP,一定是放弃了一些TCP重要的东西,比如以下两种情况:
- 业务逻辑上允许信息丢失,例如在同步状态中,状态信息是有实效性,那么过期的信息是可以允许丢失的,每个新的状态信息都可以取代旧的信息,只是允许这样操作的业务场景非常少。
- 允许包乱序,只要和TCP一样在每个包上加上个序号即可,这样的复杂程度也很高,和TCP对比起来唯一的优势也就是在即使中间有包晚到了,业务层也可以先开始处理后面先到的包开始处理。