《高性能MySQL》阅读笔记 第六章 查询性能优化
6.1 慢查询原因
查询任务由无数个子任务组成,需要优化或者消除其中的一些子任务,或者减少执行次数。这就需要我们了解查询的生命周期、清楚查询的时间消耗。这其中的时间消耗可能在网络、CPU计算、统计信息和执行计划的生成、锁等待,需要对查询进行剖析才能定位到优化点。
6.2 慢查询基础:优化数据访问
分析低效查询从两个角度来看:①应用程序是否检索了大量的超过需要的数据量;②MySQL服务器是否分析了大量的超过需要的数据量。
6.2.1 请求了不需要的数据
- 尽量在查询后面加上limit限制;
- 多表关联查询时只返回特点的列;
- 减少使用SELECT *,让优化器能够实现索引覆盖扫描,减少修改带来的问题;
- 应用中多次查询同一个数据,可以改为初次查询时将数据缓存起来
6.2.2 MySQL扫描了额外的数据
- 响应时间 = 服务时间 + 等待时间;
- 最理想的情况是扫描行数和返回行数相同。EXPLAIN语句中的type反映了访问类型,有全表扫描、扫描索引、范围访问、单值访问等;rows反映了预估访问行数。
- MySQL应用WHERE的三种方式,从好到坏:①存储引擎层过滤不匹配的记录 ②使用索引覆盖扫描 ③在MySQL服务层先从数据表读出记录然后过滤
6.3 重构查询的方式
重构可以理解为转换一种写法,从应用角度完成修改。
- 一个复杂的查询还是多个简单的查询?一个复杂的大查询,例如删除操作,一次性完成的话会一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的查询。
- 将复杂查询进行分解和切分可以带来很多好处:①单表缓存数据的使用 ②减少锁竞争 ③更容易对数据库进行拆分 ④使用IN ()代替原本的表关联更高效 ⑤关联查询会有冗余记录的查询
6.4 查询执行的基础
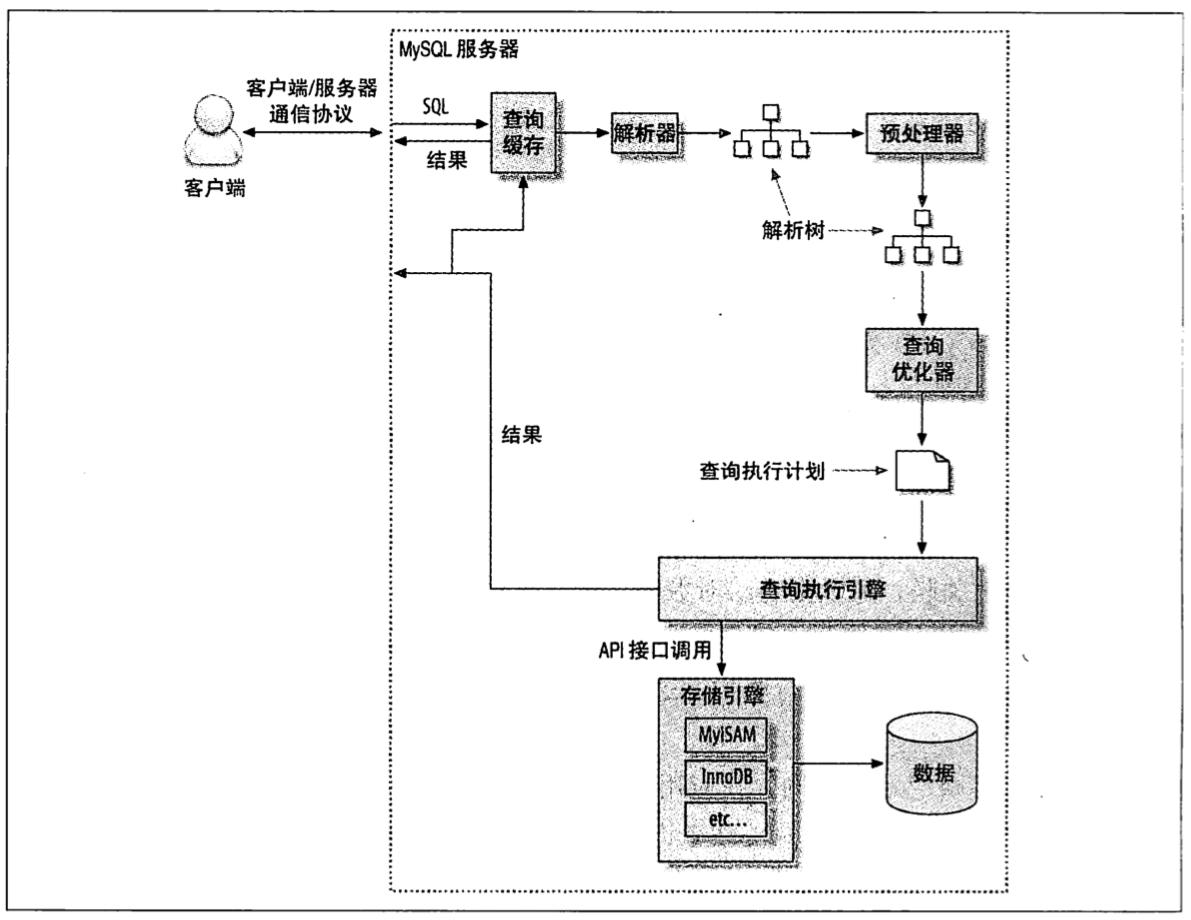
MySQL执行一个查询的过程:
- 客户端发送查询给服务器
- 服务器先查询缓存,命中则返回,未命中继续
- 解析SQL、预处理,送至查询优化器生成执行计划
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询
- 结果返回客户端结果
6.4.1 客户端/服务器通信
通信是半双工的,双方都可以发送数据,但同一时刻只有一方可以发送。没法进行流量控制,因此会涉及到数据包很大必须全部传完才行的问题。
6.4.2 查询缓存
查询缓存若打开会优先检查是否命中缓存中的数据,检查是通过一个大小写敏感的哈希查找实现。在缓存命中的情况下,查询的SQL语句都没有被解析,也不会生成执行计划,缓存中的结果直接返回给了客户端。
6.4.3 查询优化处理
这一步主要将SQL转换成一个执行计划,包含了几个子阶段:解析SQL、预处理、优化SQL的执行计划。
6.4.3.1 语法解析器和预处理
通过关键字将SQL解析成一颗“解析树”,这一部主要检查解析树是否合法,例如表列是否存在等等。
6.4.3.2 查询优化器
基于成本,预测多种执行计划的成本,并选择成本最小的那一个,计算依据有:表或索引的页面数、索引基数、索引和数据行的长度、索引分布情况;
优化策略又分为静态、动态优化,静态直接对解析树进行分析,只需要做一次,动态优化和上下文有关,每次执行时都需要评估。
MySQL能够处理的一些优化类型:重新定义关联表顺序;将外连接转化为内连接;等价条件变化,比较的合并和减少;MIN、MAX等可以依靠B-Tree索引特点快速获取,COUNT根据存储引擎单独存储的值直接获取;预估并参数化表达式;覆盖索引返回;条件得到满足就立即停止查询;关联查询的条件可以扩展到多个表上;IN条件进行二分查找优化。
6.4.3.3 数据和索引的统计信息
查询优化器在MySQL架构中的服务器层,但是服务器层没有保存数据和索引统计信息,存储引擎会提供给优化器表或索引的页面数、索引基数、数据行、索引长度和索引分布等等。
6.4.3.4 MySQL如何关联查询
关联查询不一定要两个表,每个查询都是一次关联,读取结果临时表也是一次关联。MySQL对任何关联都执行嵌套循环关联操作,也就是先从一个表中取出单条数据,嵌套到下一个表中寻找匹配的,直到找出所有的行,然后返回查询中需要的各个列,整体上都是一个”嵌套循环关联“。
可以通过如下很好的了解:

例如如上查询,MySQL实际执行时总是从一个表开始一直嵌套循环、回溯所有关联:

实际表之间的关联顺序也可以被MySQL优化,表的关联顺序不一定按照自己定的顺序决定,MySQL会根据索引、扫描的行数选出最合适的顺序来进行更少的嵌套循环和回溯操作。
6.4.4 查询执行引擎
MySQL的查询计划是一个数据结构,不是其他关系型数据库那样的字节码。
6.4.5 返回结果给客户端
如果查询可以被缓存那么MySQL这个阶段也会将结果放到查询缓存中,返回过程是一个增量、逐步的过程,
6.5 查询优化的局限性
- 关联子查询
对于Exists和In中的子查询采用如下策略:
Exists执行顺序如下:①首先执行一次外部查询 ②对于外部查询中的每一行分别执行一次子查询,而且每次执行子查询时都会引用外部查询中当前行的值。 ③使用子查询的结果来确定外部查询的结果集。
IN的执行过程如下: ①首先运行子查询,获取子结果集 ②主查询再去结果集里去找符合要求的字段列表,符合要求的输出,反之则不输出。
一般情况下,自己在选择的时候子查询表相对较大时选择exist,相对小时选择in。但这肯定不是绝对的,在实际中要测试验证执行计划和相应时间的假设。
- UNION的限制
MySQL无法将限制条件从“外层”推到“内层”,例如两表UNION操作,外层有一个limit操作,实际运行两表读取的行数不受limit影响,再两表组合成一个巨大的临时表后才会进行limit操作。
需要在UNION的两个子查询分别加上limit来解决。
- 索引合并优化
合并索引的特性在于查询一个表时,AND和OR条件两边对应的是两个不同的索引,MySQL会分别利用两个索引查出结果,然后相应的做交集并集操作。
当两个索引的值选择性较高时,各自返回的数据较少,交集并集的操作成本也低,但是如果选择性不高,各自数据量大,合并索引也会带来效率的负增长。实际工作上,多数会选择关闭合并索引功能,在实际需要使用时改写SQL,将需要合并索引的地方写为UNION操作。
- 等值传递
如果有一个非常大的IN()列表,当优化器发现存在WHERE、ON或者USING子句时,会将这个列表的值和另一个表的某个列相关联,会将IN()列表都复制应用到关联的各个表中,列表很大时会导致优化和执行都变慢。(问题出现很少见)
- 并行执行
MySQL无法利用多核并行执行查询
- 哈希关联
MySQL不支持哈希关联,MySQL所有的关联都是嵌套循环关联。
- 松散索引
MySQL不支持松散索引扫描,无法按照不连续的方式扫描一个索引。简单来说也就是不支持跳过组合索引的前部分,必须使用全表扫描来获取数据。
- 最大值和最小值化
例如在查询一个主键的最小值时,在全表扫描的情况下,理论上读到的第一个满足条件的数据就是主键的最小值,因为主键是严格按照大小顺序排列,但是MySQL这时只会做全表扫描。
- 在同一个表上查询和更新
MySQL不允许同一张表同时做查询和更新,但有一种情况可以解决这样的问题,将此表作为一个临时表,在查询之后和需要更新的表做关联操作,使得更新到表只是一个临时表。
6.6 查询优化器的提示
这部分介绍了若干的执行计划调整方法,如果对优化器给出的执行计划不满意的话可以在SQL语句上加上一些提示语句,通过提示提供给优化器一些特殊情况下选择某种查询计划的指导,规划一个比优化器自己选择的更好的执行计划。
6.7 优化特定类型的查询
6.7.1 优化COUNT()
统计行数时COUNT(*)的性能会优于括号内指定了一个列。
COUNT在统计列值时要求列值不能为null。
偶尔也可以考虑使用近似值,例如统计COUNT值时采用EXPLAIN的优化器扫描值,或者去掉一些DISTINCT之列的约束来大大减少运行时间,得到几乎相同的运行结果。
更好的优化点还有选择索引覆盖扫描,新增加一个汇总表,增加一个外部缓存等等。
6.7.2 优化关联查询
表A,B关联时,如果优化器的关联顺序是B、A,那么在ON或者USING上的列就只需要在A表上创建索引。
GROUP BY和ORDER BY尽可能只使用一个列,这样才有可能使用索引优化。
注意关联类型。
对于存在子查询的情况是,记得同时考察下转化为使用关联查询替代,说不定会有更好的效率。
6.7.3 优化GROUP BY和DISTINCT
当GROUP BY无法使用索引时会使用临时表或者文件排序来完成分组。
如果GROUP BY后没有通过ORDER BY显示指定排序列,默认排序会使用文件排序自动按照分组的字段进行排序,如果不需要排序可以使用ORDER BY NULL不使用文件排序。
6.7.4 LIMIT分页优化
如果在进行分页查询时,如果偏移量非常大(翻页翻到非常后面的页),代价会非常大。较简单的方法就是尽可能使用索引覆盖扫描,然后做一次关联操作,这样就避免了前面在翻页时查询所有的列,也叫做“延迟关联”,先定位到要访问的记录然后关联列会原表查询所有的列。
6.7.5 优化UNION操作
UNION操作都是创建并填充临时表的方式来操作,如果不是确定要取出重复的行话可以使用UNION ALL代替,因为没有ALL的话MySQL会给临时表加上DISTINCT操作,代价会非常高。
6.7.6 语句中的自定义变量
有这些场景不能使用自定义变量:
- 使用了自定义变量不能查询缓存
- 不能在常量或者标示符的地方使用自定义变量(表、列名,LIMIT子句中)
- 自定义变量的生命周期是一个数据库连接中
- 自定义变量在MySQL 5.0之前对大小写敏感
如果用MySQL构建队列表,历史已完成消息归档、和未处理的消息分表。
总结
好好理解解析优化过程的知识,可以帮助更好的理解表和索引的内容。优化的三点建议:不做、少做、快速的做。例如,不做-查缓存,少做-减少扫描等等这些。
Ref
BaronSchwartz, PeterZaitsev, VadimTkachenko, et al. 高性能MySQL[M]. 电子工业出版社, 2013.